This feature is currently available only on the US1-East and Demo environments.
Overview
As OCP® expands to more diverse industries, supporting every use case with completely custom Automatic Speech Recognition (ASR) models becomes more challenging. To address this, the ASR adaptation feature enables self-service creation of grammar-based ASR models tailored to a user's specific OCP miniApps® scenarios.
This guide outlines the process for adapting the Speech-To-Text (STT) grammar using user-provided NLU corpora. By training ASR grammar directly from the same dataset used to train the NLU model, this approach ensures consistency between intent recognition and voice transcription, improves ASR accuracy for domain-specific vocabulary, and establishes a single source of truth for both NLU and ASR.
Important Notes
The current version is intended primarily for controlled testing, internal demos, and proof-of-concept use cases. It is not yet suitable for complex or production-critical deployments.
-
Language & Domain: The following locales are supported only within the universal domain:
-
en-US
-
en-AU
-
-
Model Deployment: Manual updates to deployed ASR models are not supported. Any changes require creating and deploying a new model.
-
Recognition Scope: The ASR engine performs reliably only when the spoken input closely matches the NLU corpus text. Out-of-corpus phrases may result in recognition challenges.
Before starting the adaptation process, an administrator enables the ASR adaptation feature for the relevant group in the NLU admin area.
Key Concepts
-
ASR Adaptation: Refers to the process of compiling an STT grammar to better handle new or domain-specific terms introduced by the user. It uses the same training data as the NLU model for tighter integration and improved accuracy.
-
Grammar Compilation: Converts the intent and utterance data from the NLU corpus into a format optimized for the speech recognition engine.
-
OCP Conversational Speech-To-Text® model (STT Model): A customized speech model that reflects the vocabulary and structure used in miniApps, enhancing performance in voice-based interactions.
ASR Adaptation Process
To adapt the ASR grammar to an NLU model, follow the instuctions below:
-
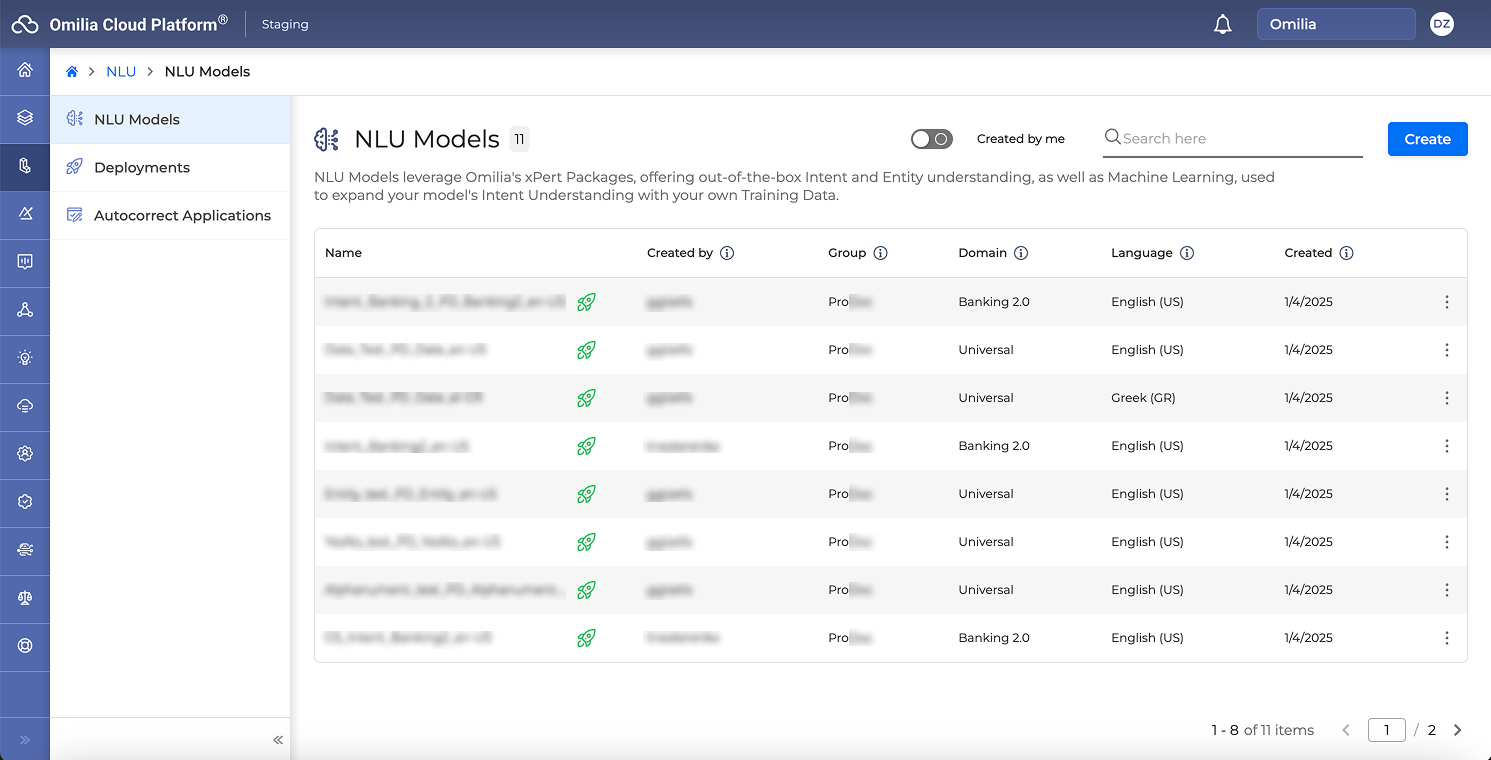
Access the created NLU model or create a new one:
-
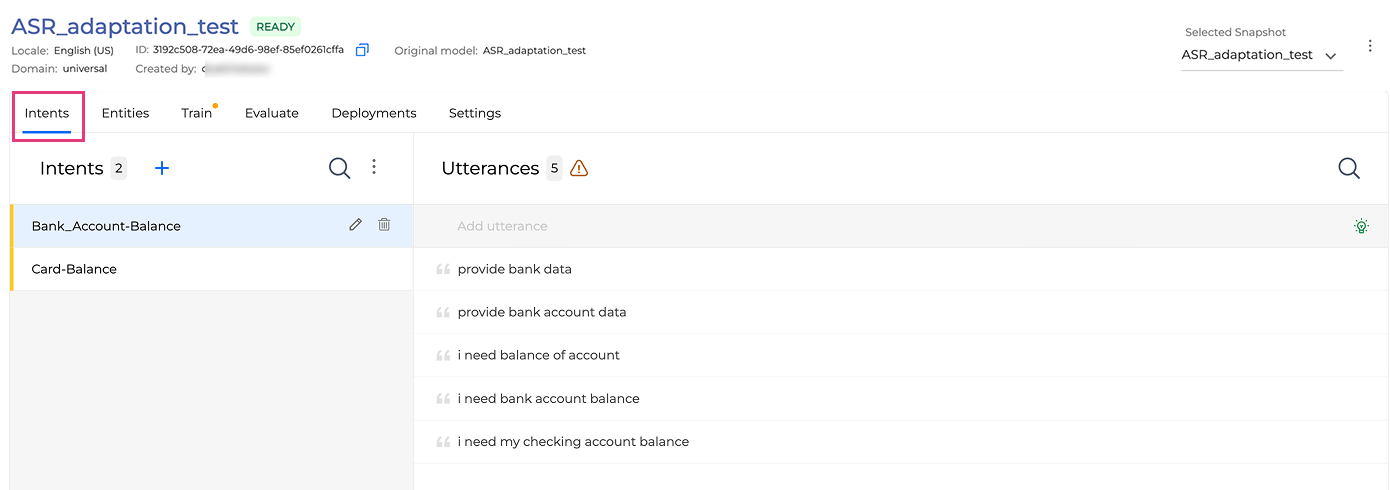
Add intents and utterances:
-
To add intents, follow the instructions: Adding custom data to an NLU model | Adding intents .
-
To add utterances, refer to the guidelines: Adding custom data to an NLU model | Adding utterances.
-
-
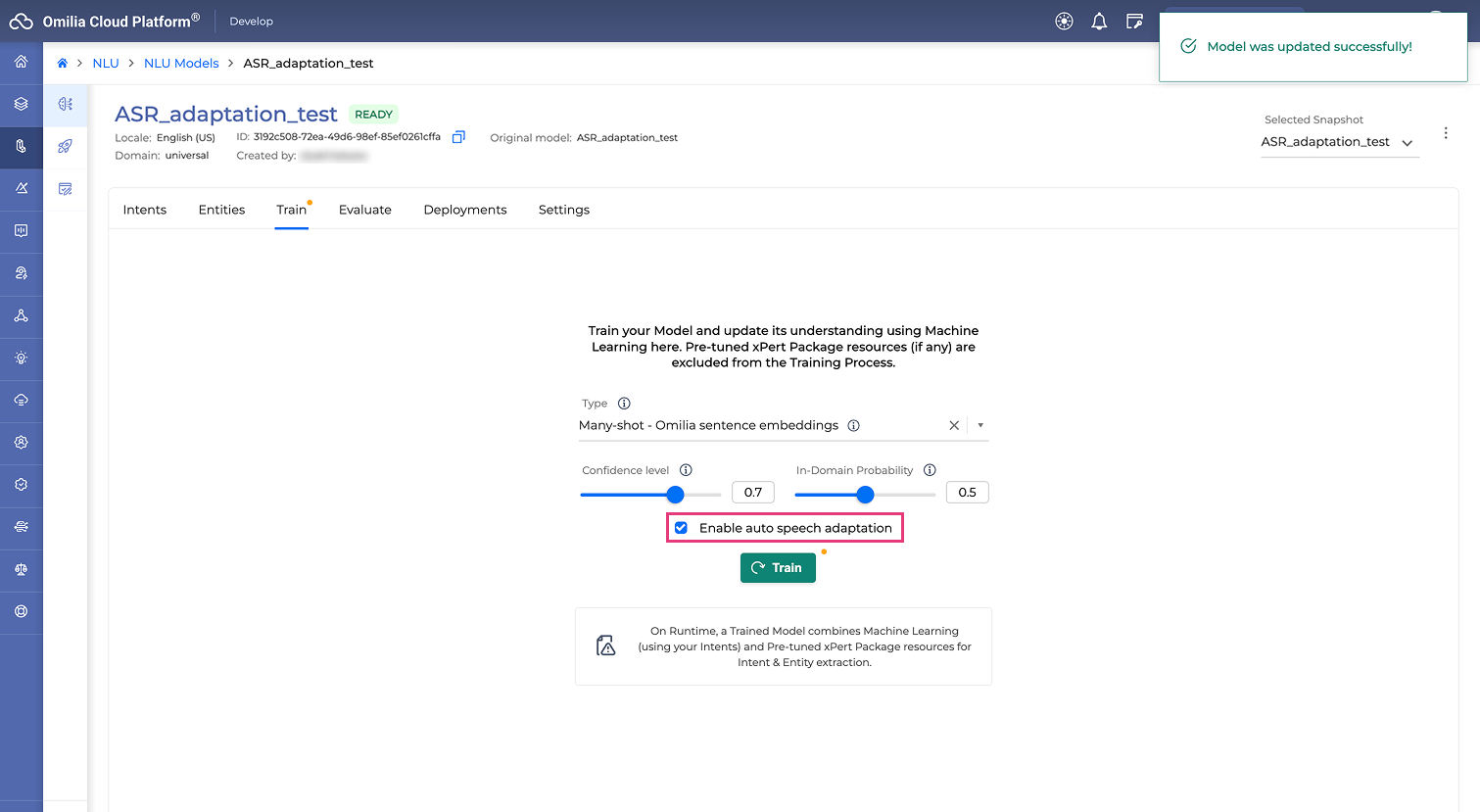
Enable Auto Speech Adaptation:
-
Go to the Train tab.
-
Mark the Enable auto speech adaptation checkbox.
-
Click Train to start the grammar compilation and the NLU model training.
-
-
Deploy the NLU model as described in Deploying a model.
-
Link the miniApp with a deployed NLU model:
-
Navigate to miniApps and open the miniApp you wish to link.
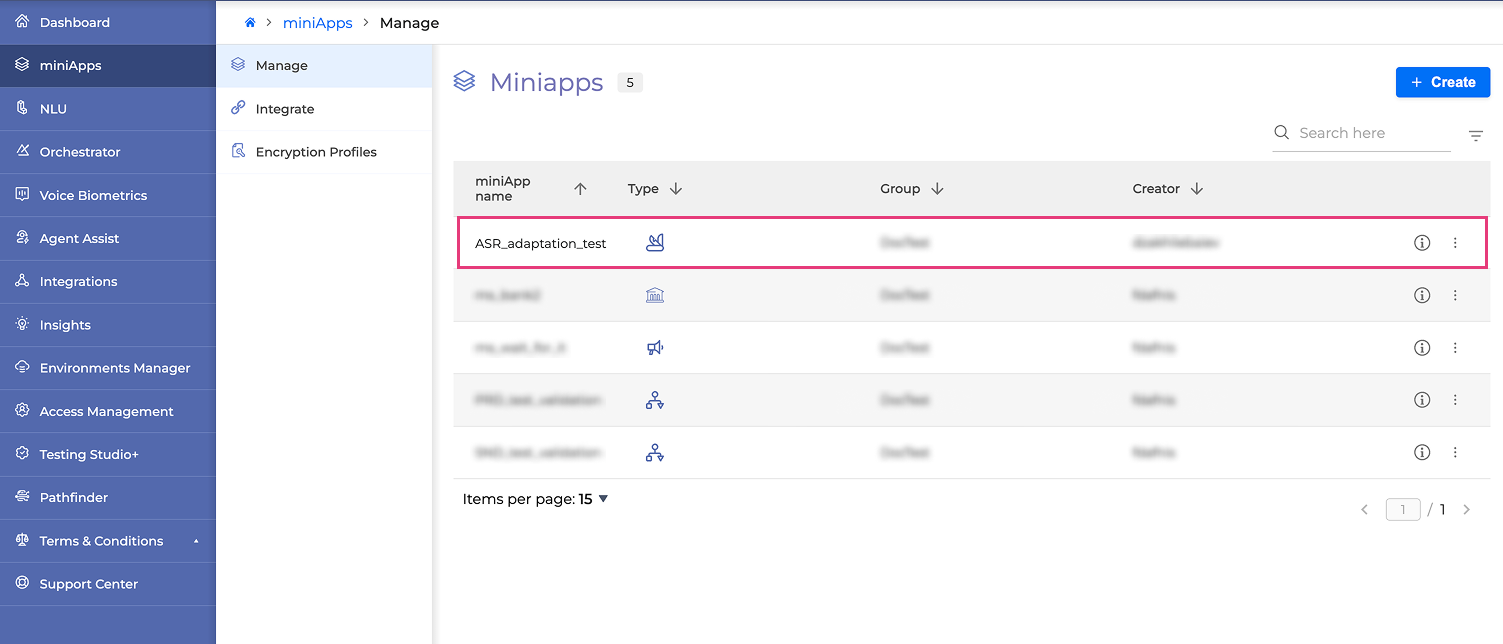
-
Go to the Manage Intents tab and click on Natural Language Understanding.
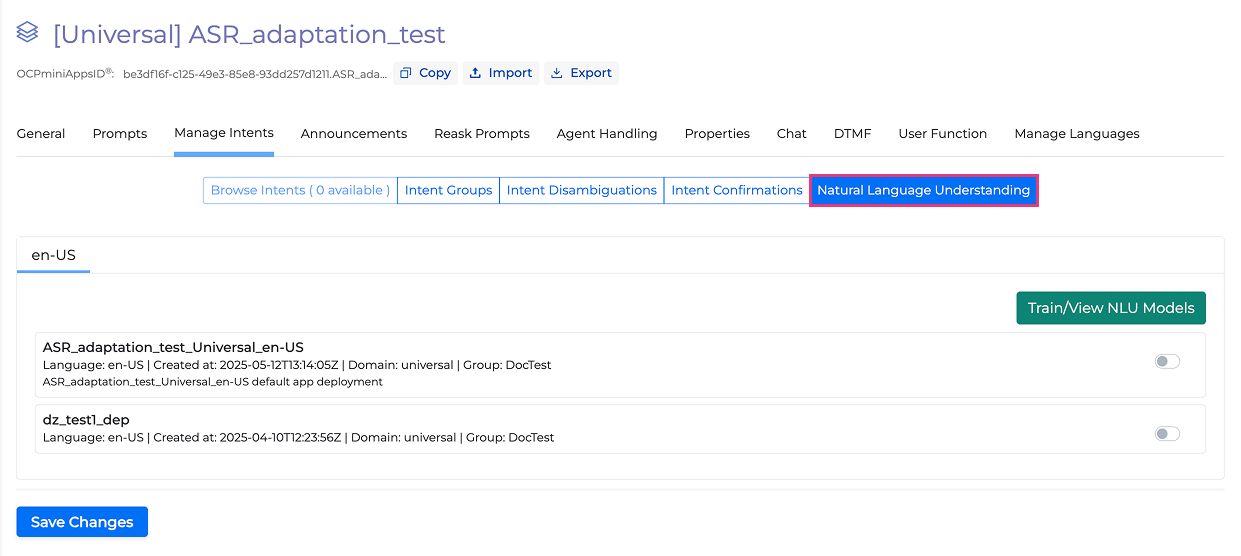
-
Find the deployed NLU model and toggle it on.

-
Click on Save Changes.
-
Ensure that the linked NLU model has the Auto Speech Adaptation feature enabled: ASR Adaptation User Guide | Enable Auto Speech Adaptation.
-
If you select an NLU model with an associated custom ASR grammar, a pop-up will ask you to link the ASR Grammar to the miniApp.
Once you confirm, the custom ASR grammar is linked. It will then appear in the Manage Languages > Custom Grammar tab and will automatically populate the Custom Grammar field as soon as that setting is enabled.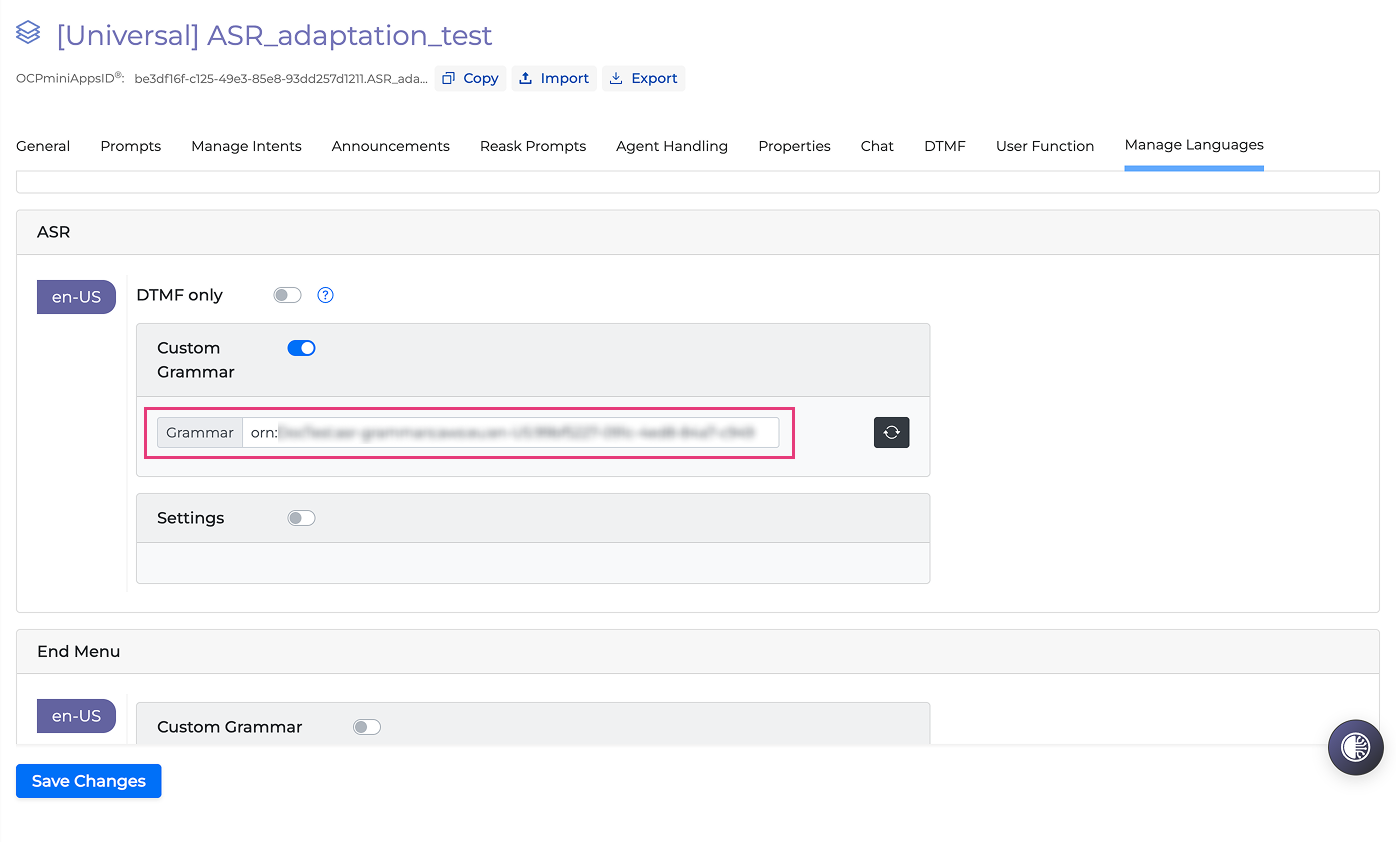
API Endpoints
These endpoints are available for grammar operations:
|
Method |
Endpoint |
Description |
|---|---|---|
|
POST |
|
Builds or compiles a grammar |
|
DELETE |
|
Deletes a specific grammar |
|
GET |
|
Retrieves the grammar status |
Refer to the miniApps API for request examples and required parameters.
Behavioral Notes
-
Deleting a deployed NLU model also deletes the associated grammar.
-
Updating an existing deployed model is not supported. Create a new model instead.
-
Grammars are stateless: they are created, used, and removed after execution.
-
If an invalid grammar is passed, the system defaults to a generic grammar.
Model Information
Once an NLU model is deployed, it receives a unique ID. This ID is used internally for Speech-To-Text model management and stored in the backend database.