NLU Model training
Train a model when you add a custom dataset for intents
The training process will expand the model’s understanding of your own data using Machine Learning.
You can also read more about training best practices.
If you have added new custom data to a model that has already been trained, additional training is required.
To train a model, you need to define or upload at least two intents and at least ten utterances per intent. To ensure an even better prediction accuracy, enter or upload more than ten utterances per intent.
Deployed NLU models cannot be trained or edited in any way. They are locked and available in the view-only mode.
K-Fold cross-validation
K-Fold cross validation is suggested to run prior the training in order to get the optimal threshold for the training.
The K-Fold Validation Results area in the Train tab allows you to evaluate the performance of your NLU model using K-fold cross-validation.
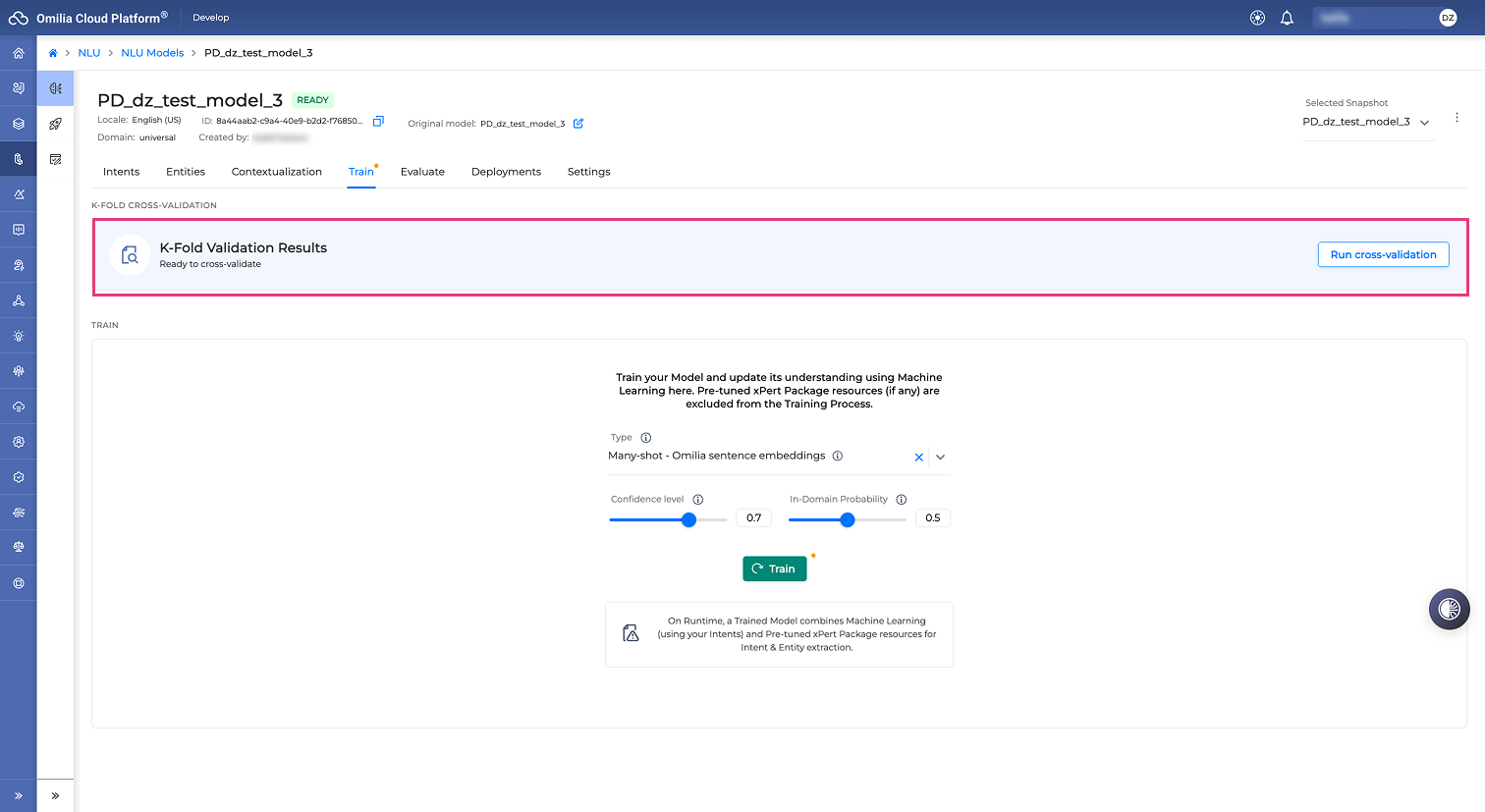
To run a K-fold cross-validation, your NLU model must contain at least two intents, and each intent must have seven or more utterances. If your model does not meet these requirements, the system displays an error.
Running cross-validation
To run a cross-validation, follow these steps:
-
Navigate to the Train tab.
-
Сlick Run cross-validation.
While the cross-validation is running, the system displays a progress indicator.
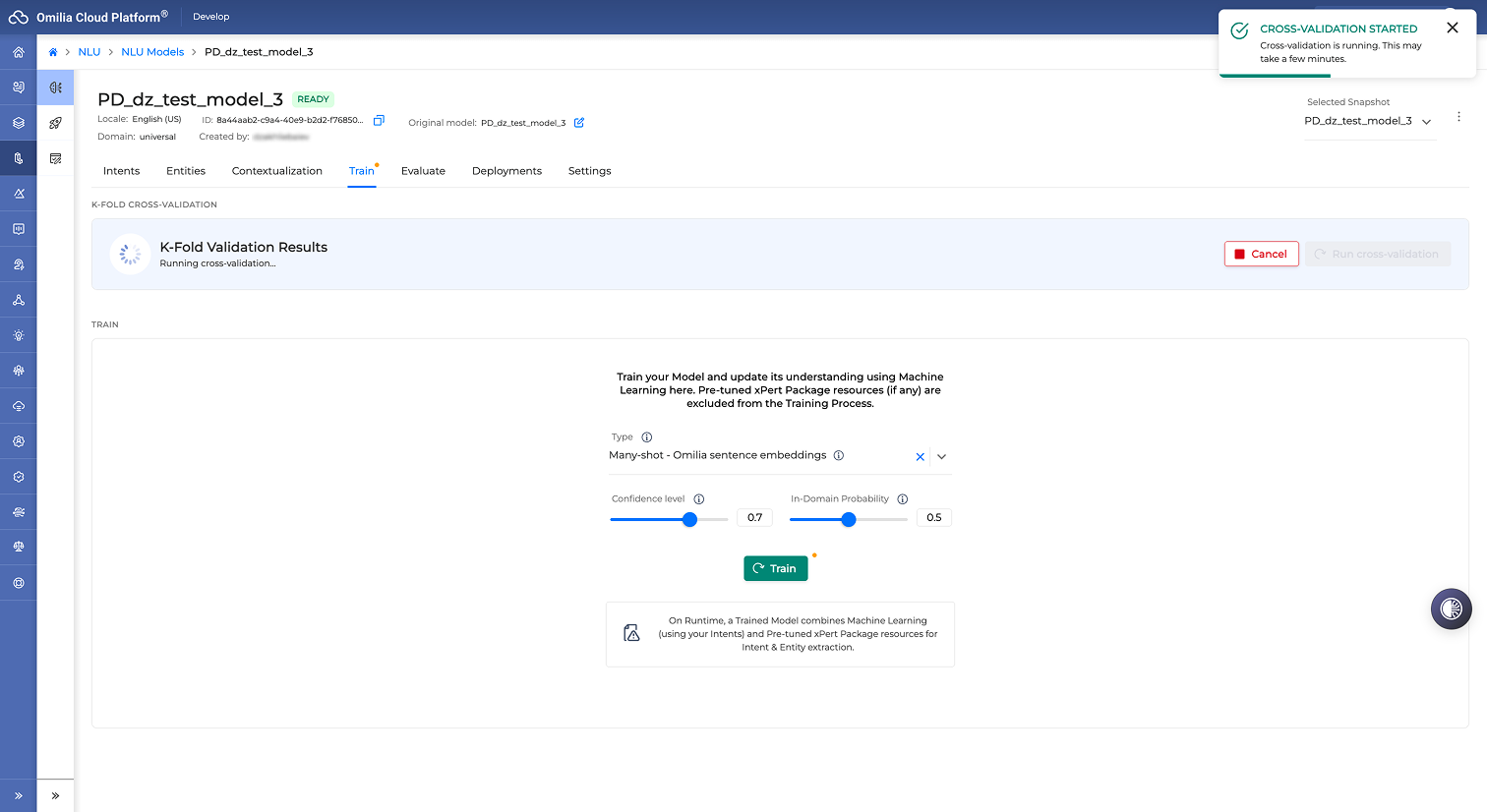
You can select Cancel to stop the process after 5 minutes of validation.
Viewing cross-validation results
When the process is complete, the area displays a summary of the results, including the number of folds, total samples, and overall accuracy.
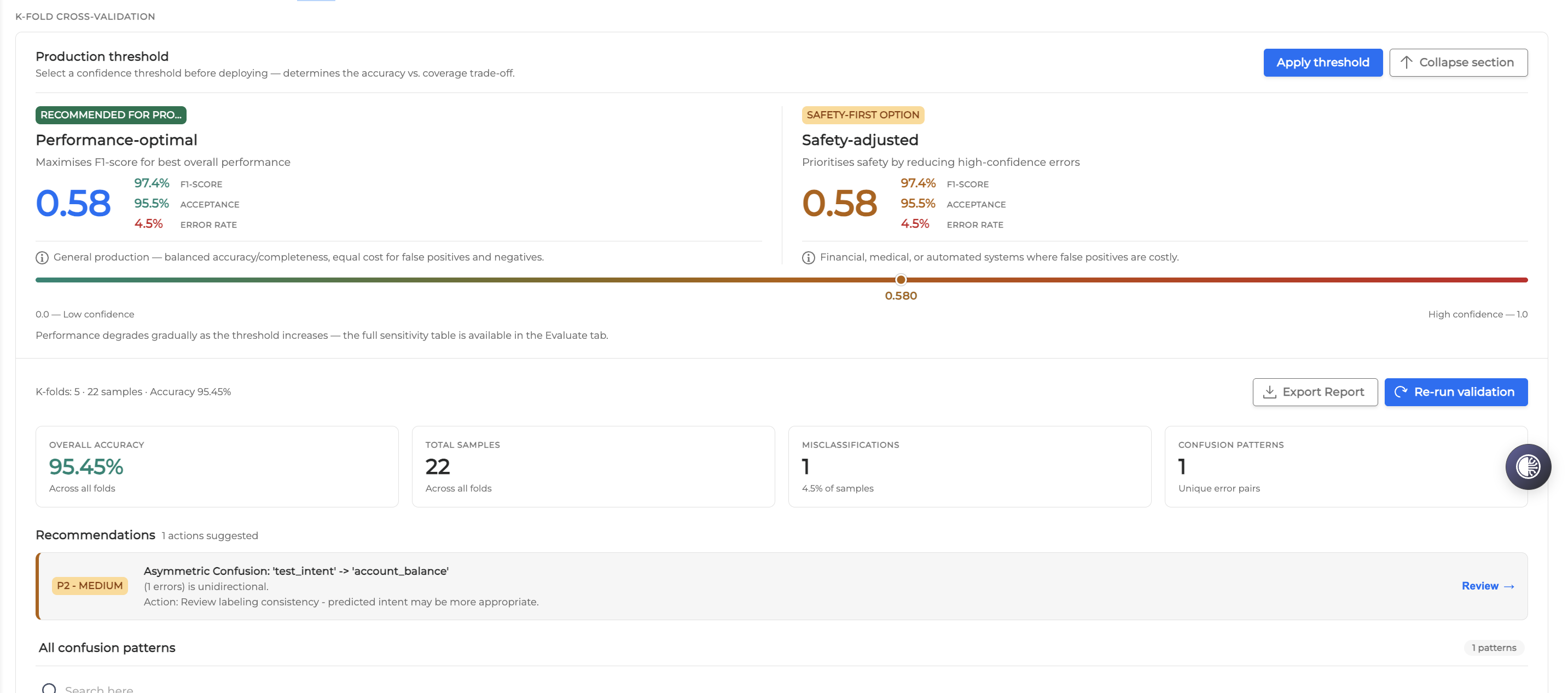
You can expand or hide the validation details using the interface buttons:
-
Select View details to expand the section and review comprehensive validation metrics, recommendations, and confusion patterns.
-
Select Collapse section to hide the details.
The Recommendations section provides suggested actions to improve your NLU model based on the cross-validation results, Esuch as addressing asymmetric confusion between intents.
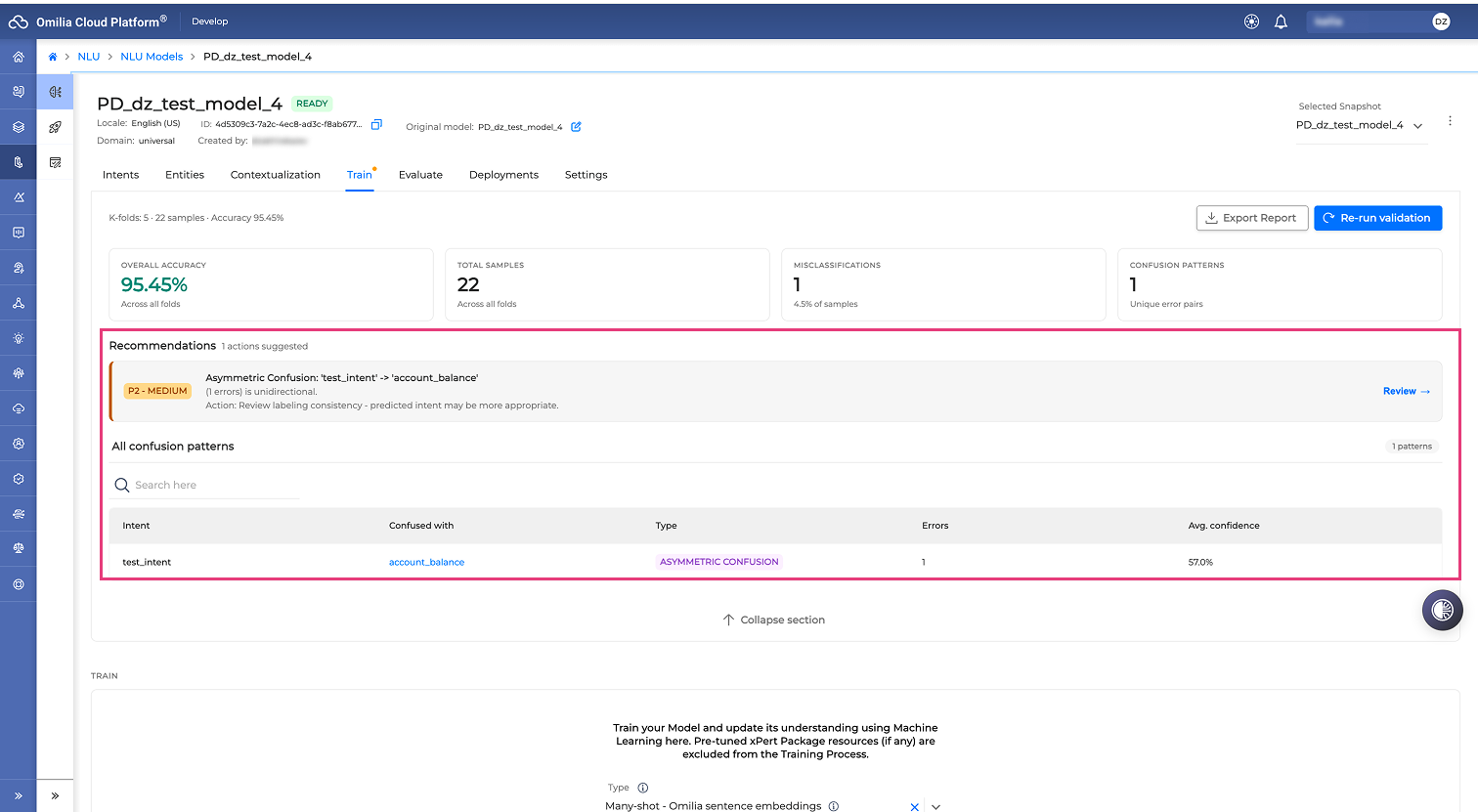
Select Review next to a suggested action to expand the item and view the relevant categories and details.

Managing validation results
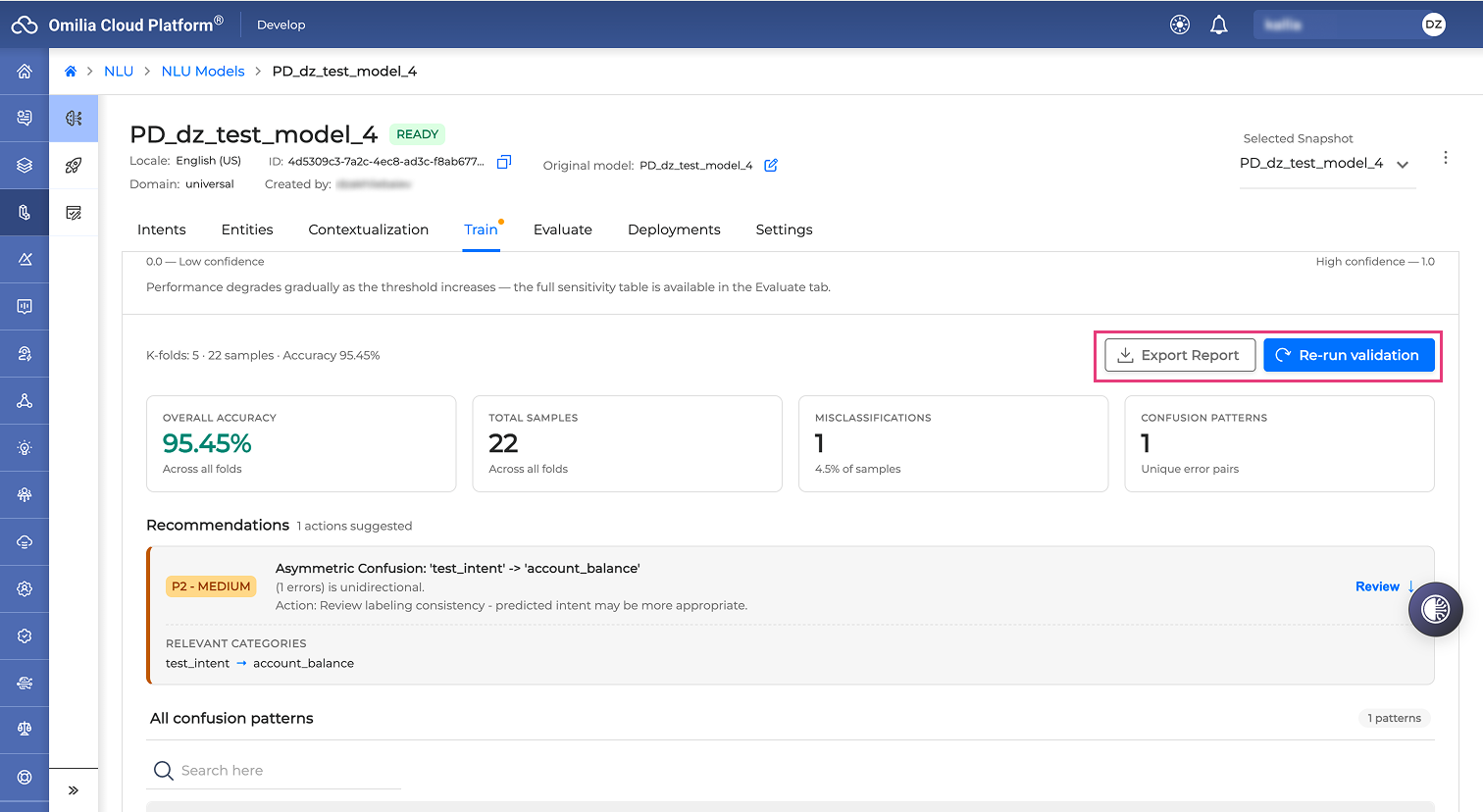
From the expanded validation results area, you can perform the following actions:
-
Select Export Report to download an archived copy of the cross-validation results.
-
Select Re-run validation to execute the cross-validation process again and update the results.
Applying a production threshold
The Production threshold section allows you to select a confidence threshold before deploying your NLU model. This configuration determines the trade-off between accuracy and coverage.
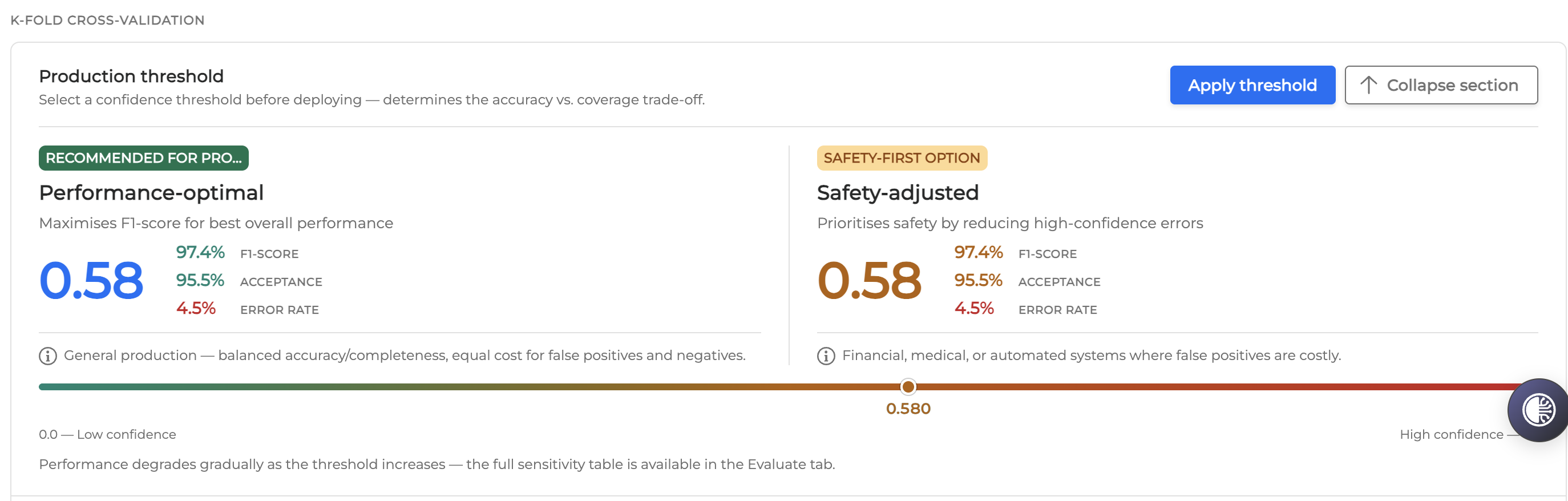
You can manually adjust the threshold using the slider, or use the interface to guide your selection between two main strategies:
-
Performance-optimal: Maximizes the F1-score for the best overall performance. This is recommended for general production.
-
Safety-adjusted: Prioritizes safety by reducing high-confidence errors. This is the safety-first option for environments where false positives are costly.
To apply a production threshold, follow these steps:
-
Select a threshold value using the slider.
-
Select Apply threshold.
When the configuration is complete, the system displays a success message confirming that the confidence threshold is applied to the model.
Training a model
To train a model, follow the guidelines below:
-
Navigate to NLU → NLU Models section and click on a selected model. The model drill-down page opens.
-
Open the Train tab.
If the Train page is greyed out, the model has already been trained.
-
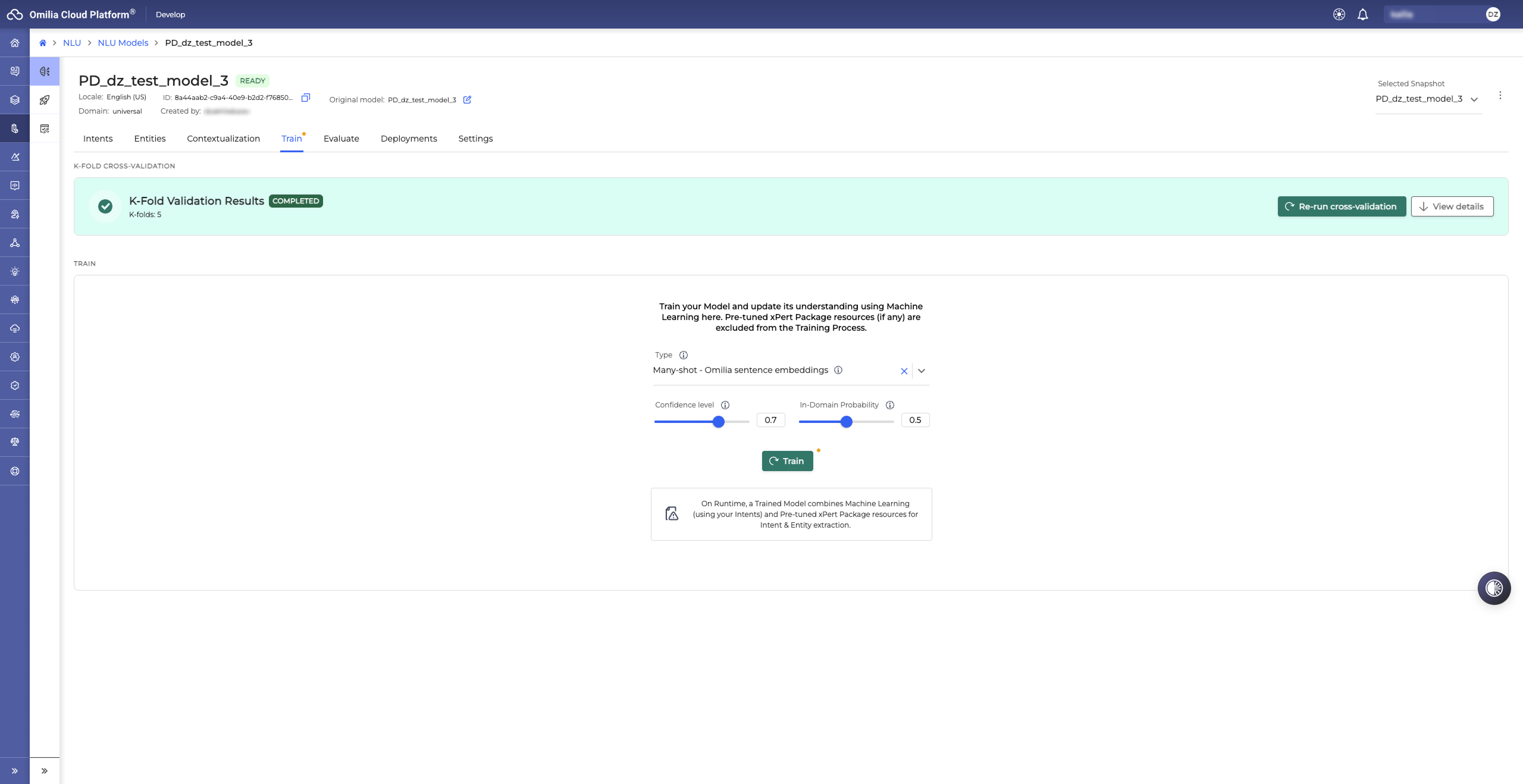
Select Type of the Machine learning encoders. You can train your model with different encoders and select the one that works best for you. The performance will increase as the size of the training set increases. Depending on the selected language, the following types are available:
-
Many-shot - Omilia sentence embeddings: Available in English. Works best for Omilia domains (for example, Banking, Energy, Telecommunications, and so on) leveraging transformer encoders with pre-trained domain-specific embeddings.
-
Contextual Intent Recognition: Available in English only for ML Server v3.3.0 and later. The model analyzes the entire conversation to identify the correct intent. Provide at least 10 training utterances.
-
Many-shot - Multilingual sentence embeddings: Suitable for all domains in languages other than English.
-
-
Select Confidence level. The confidence level defines the accuracy level needed to assign intent to an utterance for the Machine Learning part of your model (if you’ve trained it with your own custom data). By default, the confidence level is 0.7. You can change this value and set the confidence level that suits you based on the quantity and quality of the data you’ve trained it with.
The more data you train your model with, the more accurate it will be, so a more loose Confidence level (around 0.7 - 0.9) can be used. For models with a small volume of training data, a higher Confidence level must be used to avoid false predictions.
-
Select In-Domain Probability. The in-domain probability threshold lets you decide how strict your model is with unseen data that are marginally in or out of the domain. Setting the in-domain probability threshold closer to 1 will make your model very strict to such utterances but with the risk of mapping an unseen in-domain utterance as an out-of-domain one. On the contrary, moving it closer to 0 will make your model less strict but with the risk of mapping a real out-of-domain utterance as an in-domain one.
-
Optionally, you may enable ASR Adaptation.
-
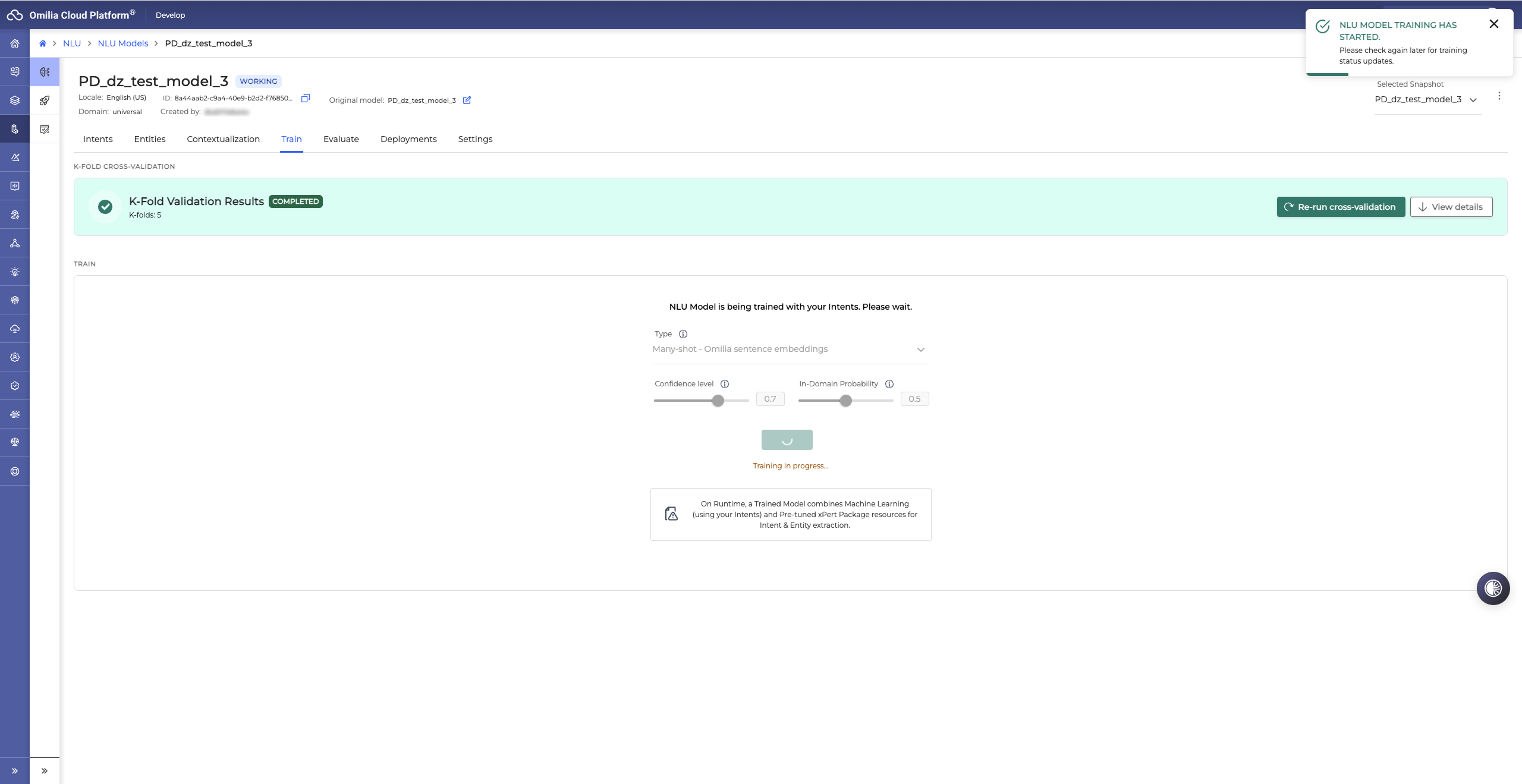
Click the Train button to start the training process. The model status changes to Working.
Depending on the training data scope, the training process can take up to several minutes.
-
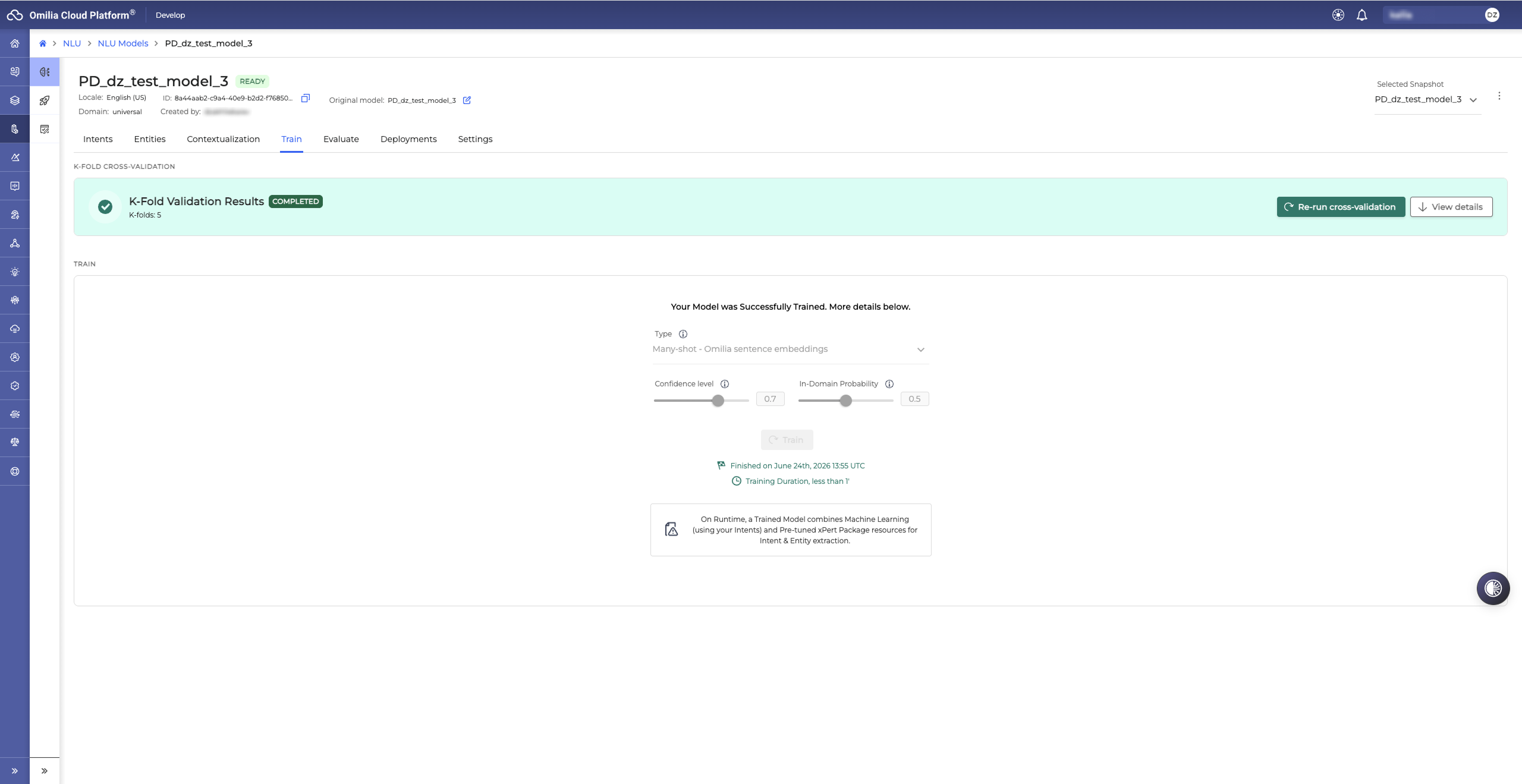
When the training is completed, the model status is set to Ready.
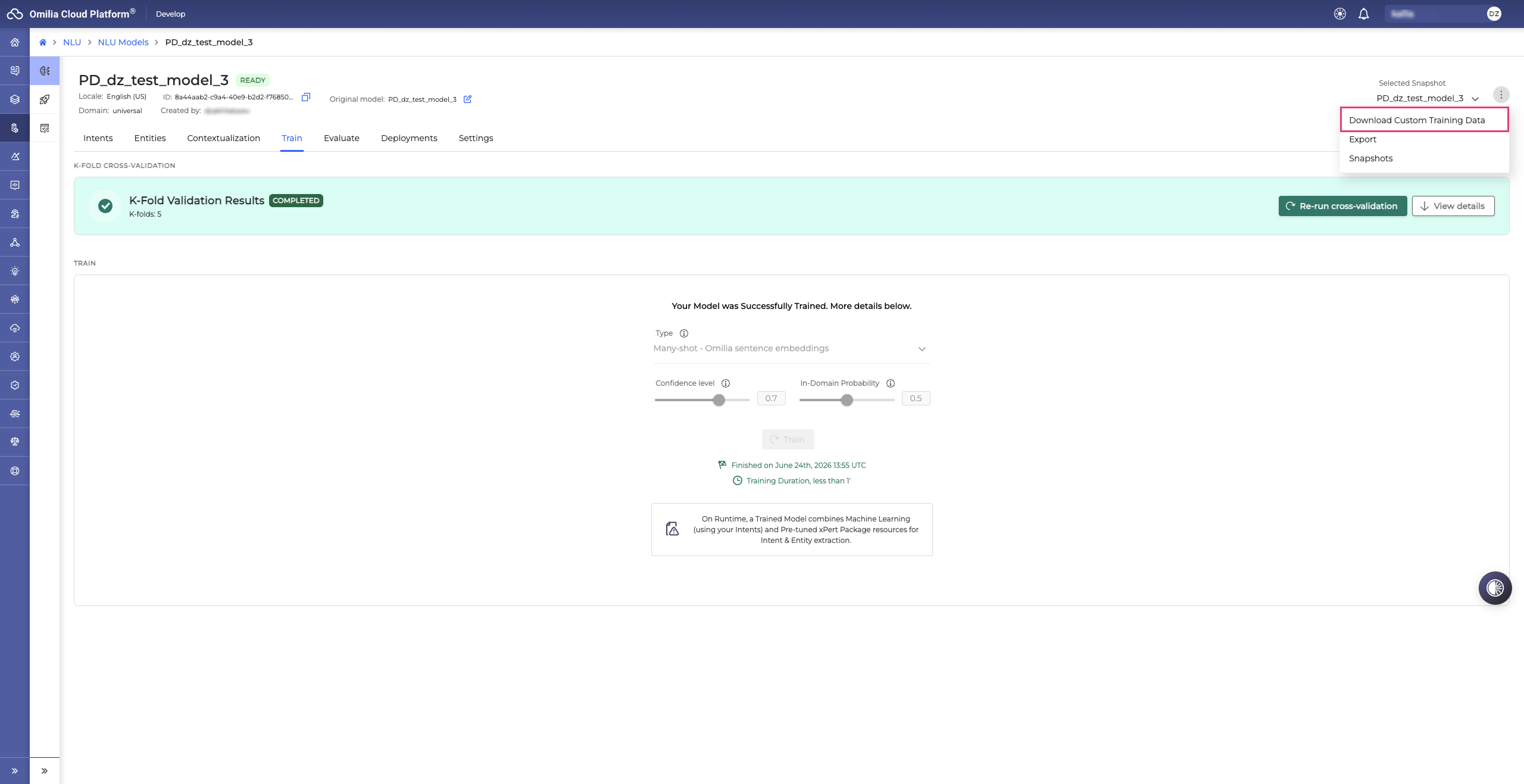
Downloading custom training data
To download your custom training data as a CSV file:
-
Navigate to NLU → NLU Models section.
-
Select a model from the list of available models and click on it to open.
-
Click the Options menu icon next to the Selected Snapshot.
-
Select Download Custom Training Data.