What is model evaluation?
Evaluating allows you to discover the performance of your model’s Machine Learning part.
Thus, evaluating a model is only possible for models expanded with custom training data.
Check out Custom data and Machine Learning best practices page for evaluation best practices.
Evaluating a model
To evaluate a model, follow the steps below:
-
Navigate to NLU → NLU Models section.
-
Select a model from the list of available models and click on it.
-
Select the Evaluate tab.
-
Select between the ML Results tab or Full Results tab.
The ML Results tab becomes active only after you train the model. The Full Results tab is always available.
-
Upload the data you want to evaluate your model with. Supported file formats are TXT, CSV, and TSV.
-
Click the Evaluate button.
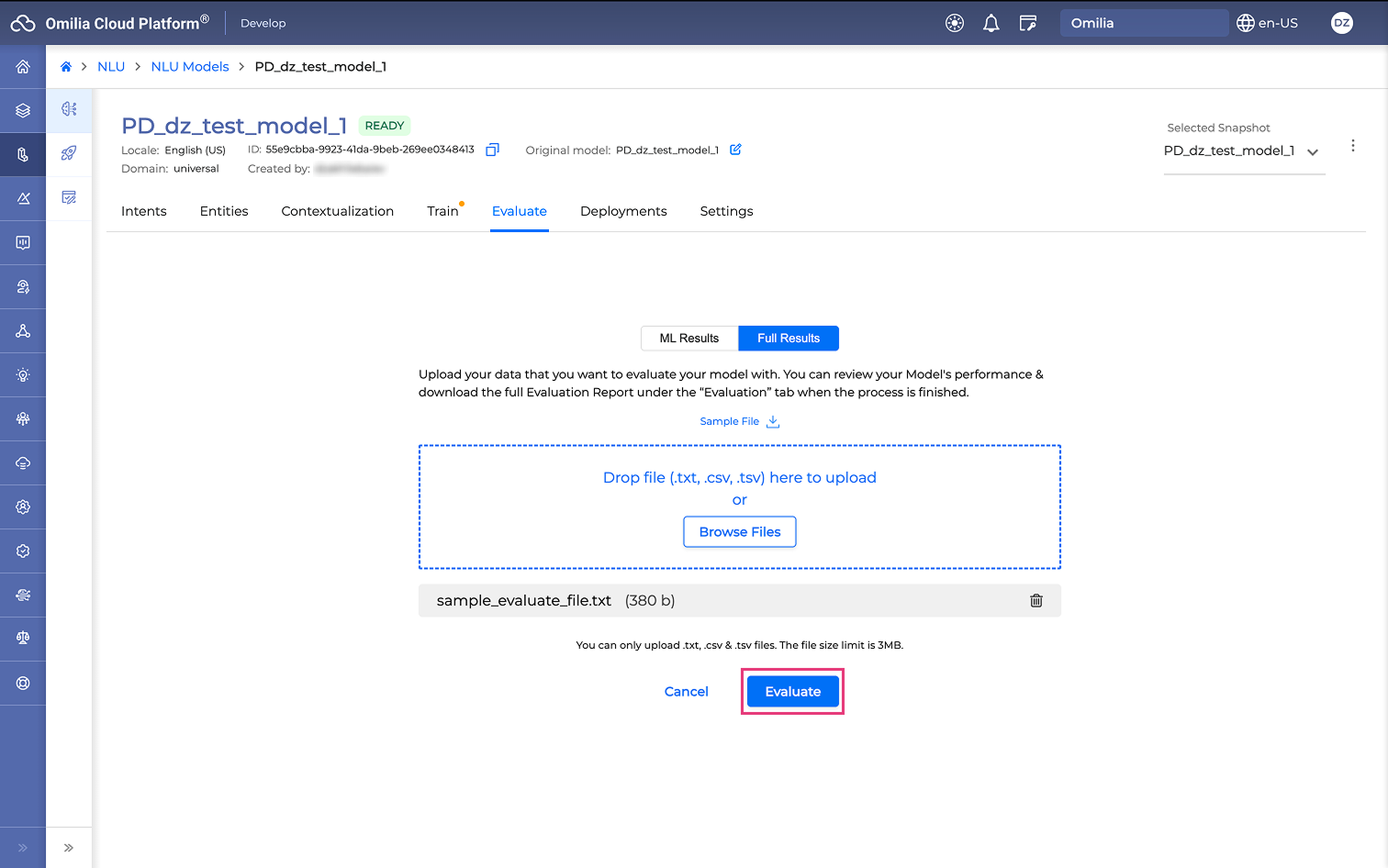
-
The evaluation starts and can take up to several minutes depending on the evaluation data scope.
-
When the Full Results evaluation is finished, the following high-level metric of the evaluation report is presented on the screen:
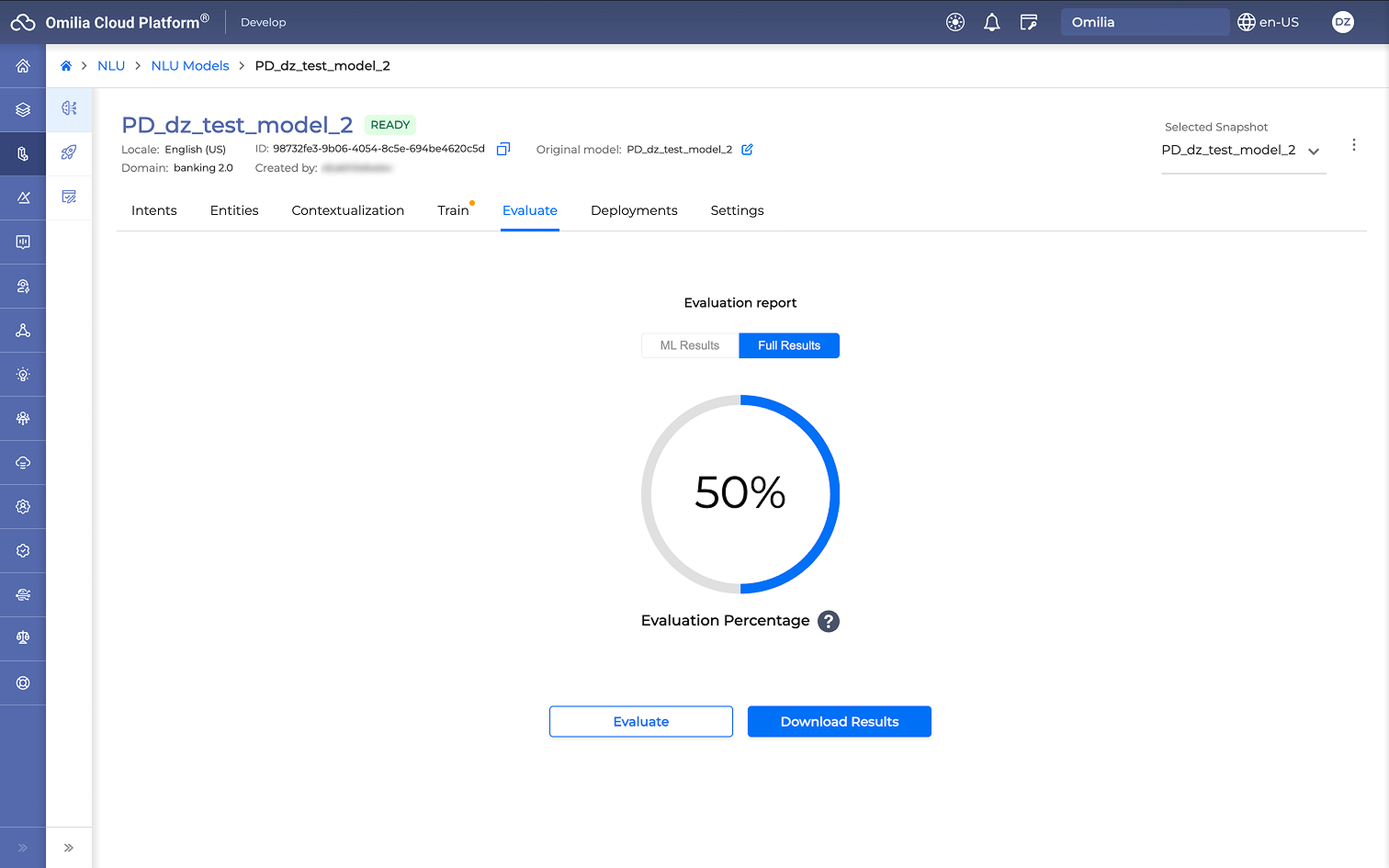
-
When the ML Results evaluation is finished, the following high-level metrics of the evaluation report are presented:
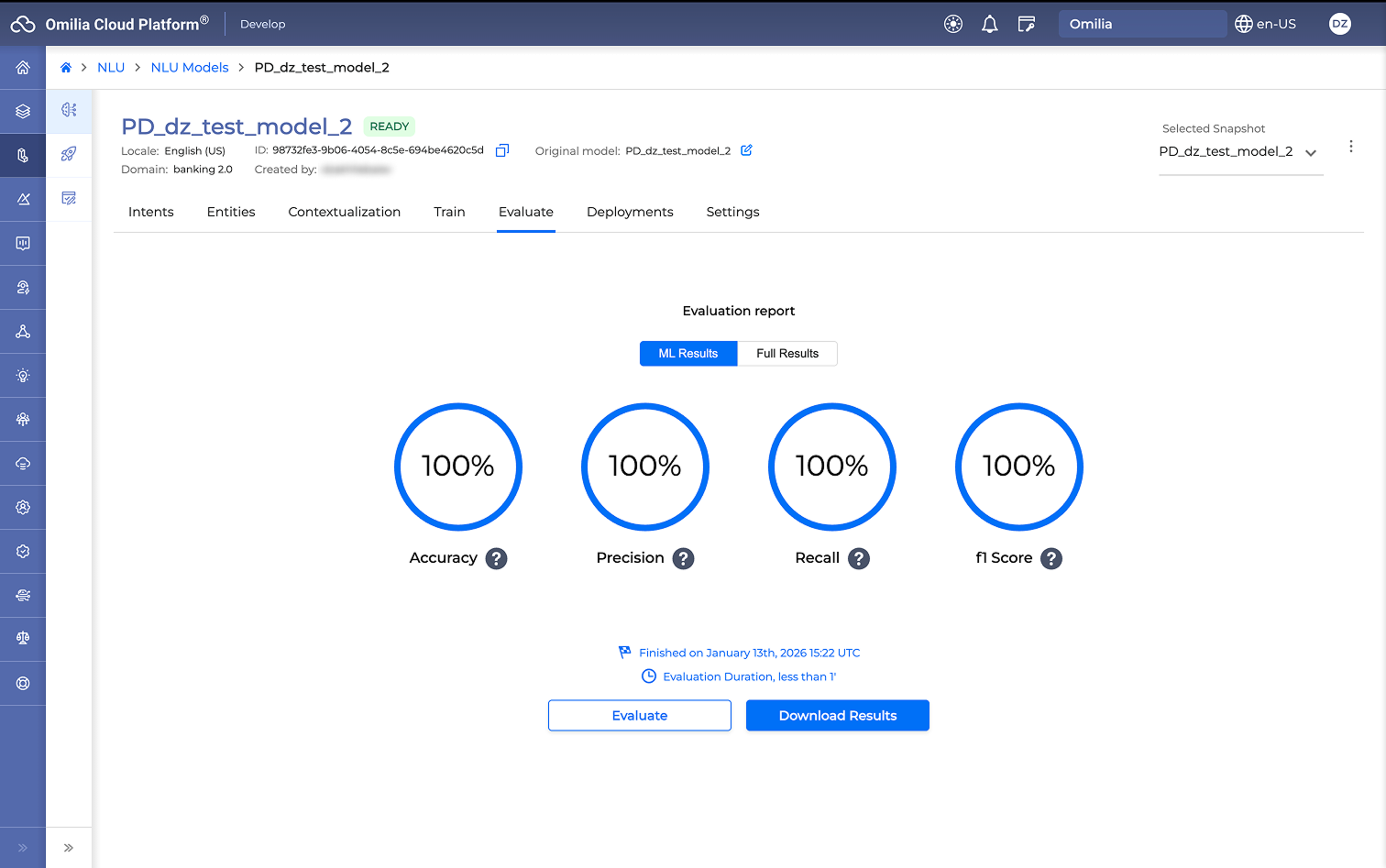
-
To download the report, click the Download Results button. The report includes detailed statistics and is available as a ZIP archive containing three TSV files.
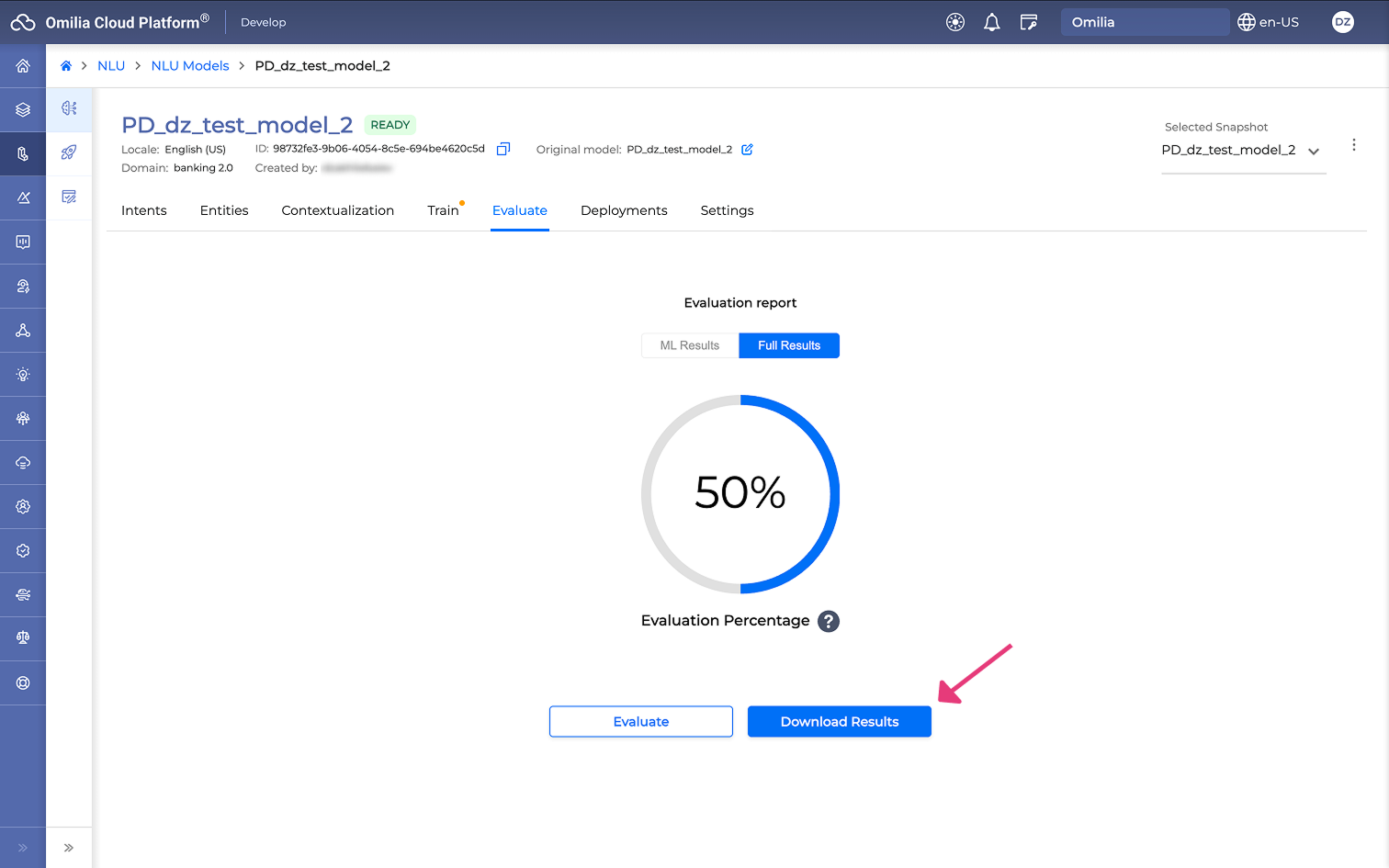
-
To repeat the evaluation, click the Evaluate button.
To evaluate a model, avoid using the data that you have used to train your model with. Make sure that your evaluation set includes data that are unseen for the Machine Learning part of your model.
Evaluation Metrics
The evaluation report presents metrics to assess model performance, categorized by the selected results tab.
ML Evaluation Metrics
The ML Results tab displays detailed statistics on the model's machine learning performance:
-
Accuracy: This is a per-model metric that represents the percentage of correct predictions made by the model out of the total predictions. It is calculated by dividing the number of correctly classified samples by the total number of samples in the dataset.
Accuracy = Number of correct predictions / Total number of test sets
-
Precision: This is a per-intent metric that indicates the model's ability to avoid labeling a negative sample as positive. High precision signifies that utterances from other classes are not incorrectly classified as belonging to this class.
Precision = TruePositives / (TruePositives + FalsePositives)
-
Recall: This is a per-intent metric that measures the model's capacity to identify all positive samples. It can be viewed as class-specific accuracy. High recall indicates that the model correctly predicts utterances that belong to the class.
Recall = TruePositives / (TruePositives + FalseNegatives)
-
F1 score: Offers a combined evaluation of both Precision and Recall to provide a more comprehensive view of the model’s performance. The F1 score is particularly useful when there is an uneven class distribution.
Fscore=2 x (Precision x Recall) / (Prescision + Recall)
Full Evaluation Metrics
The Full Results tab provides a high-level overview of the evaluation:
-
Evaluation Percentage: This metric represents the overall Accuracy of the model. It is calculated by dividing the number of utterances assigned to the correct intent by the total number of utterances in the dataset.
Accuracy = Number of correct predictions / Total number of test sets